Voice Prompts
Voice prompts are text-based prompts that the scenario will play to a caller. The scenario uses integrated text-to-speech technology to read and deliver text to a caller in any supported language. Voice prompts can be managed from any scenario block that uses prompts (e.g., Play Prompt, Play-Listen, Menu, Collect Digits, etc.).
This article describes the voice prompt management options that are available in such scenario blocks. For more information about voice prompt types please see Voice Segments.
Prompt to play
Adding, editing, and deleting voice prompts typically begins in the scenario block's properties. If there are no prompts set up for a block, the property "Prompt to play" will be blank, with the option to add a new prompt. Clicking on an existing prompt or clicking on add will bring up the Prompts list.
Prompts list
The Prompts list consists of two tabs: Prompts and Languages.
Prompts tab
From the Prompts tab, you can add and edit prompts.

Options:
- Select - Chooses the highlighted prompt from the list and closes the dialog
- Select None - Cancels the selection and closes the dialog
- Edit - Brings up the Edit prompt dialog, where you can change the voice prompt to play, upload your own voice segment (in .WAV fomat), or create additional voice segments to use
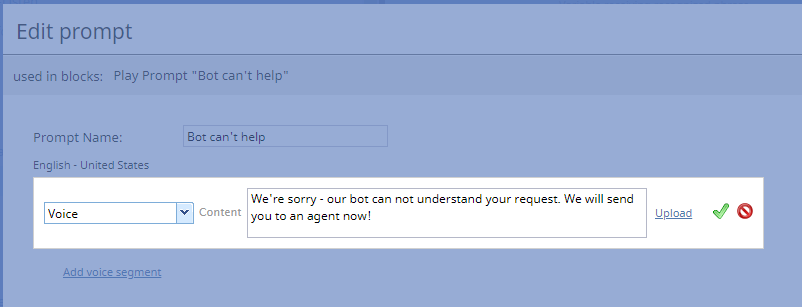
Edit prompt - Add new - Brings up the New prompt dialog, where you can create a new voice prompt to play, upload your own voice segment (in .WAV fomat), or create additional voice segments to use
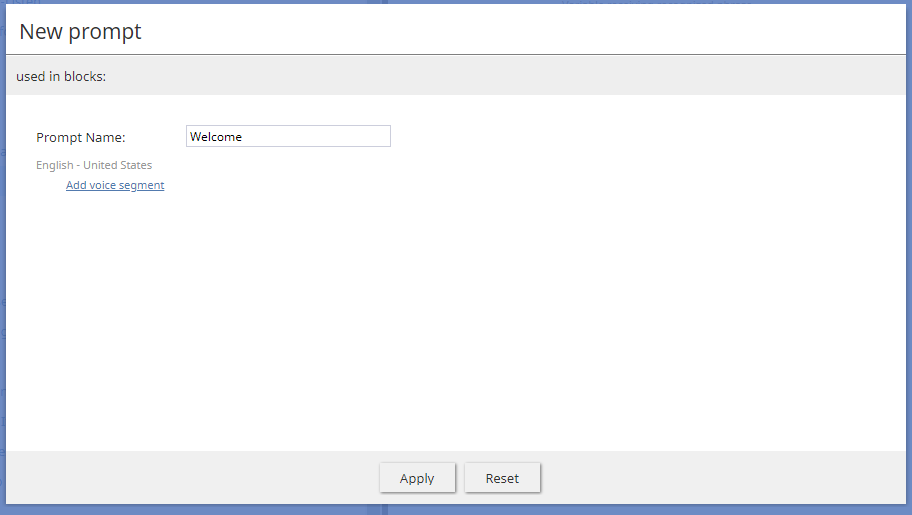
New prompt - Delete - Removes the selected prompt
- Close - Saves and closes the Prompts list
- Download for recording - In a new browser tab or window, displays the text of all prompts listed as a transcript, so you can read each prompt and record it in your own voice
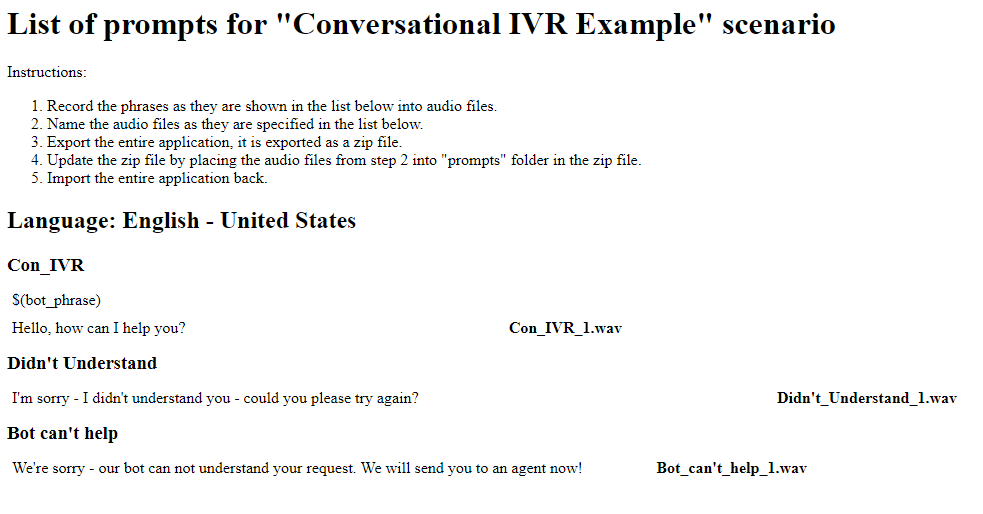
New prompt



Languages tab
From the Languages tab, you can set the language and speaking voice to use for all voice prompts.
Options:
- Default language - Set desired language for the voice prompt to be spoken in (e.g., "English - United States")
- Default TTS Voice - Set the desired speaker voice (e.g., "MicrosoftTTS(default)")
Note
If using Google or Watson TTS, you may control the speed with which text is read back using SSML tags. An example for each is shown below along with alternative values.
For Watson TTS <speak version="1.0"><prosody rate="x-slow">example text</prosody></speak> (for more information https://cloud.ibm.com/docs/text-to-speech?topic=text-to-speech-elements)
For Google Cloud TTS <speak><prosody rate="x-slow" pitch="-2st">example text</prosody></speak>
You can use one of values instead of "x-slow": x-slow", "slow", "medium", "fast", "x-fast", or "default".